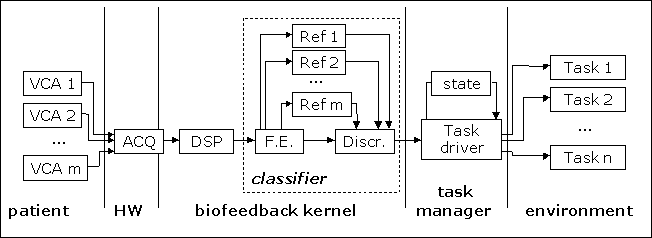
However, while the number and type of the voluntarily controlled biological signals is specific to every patient, the number of tasks that one wants to execute is quite homogeneous. Furthermore, even if the nature of the utilized signals may vary among different pathological situations, the way in which a biofeedback system works is quite stereotyped (fig. 1): after the data have been acquired, there is a DSP pre-processing stage that performs some basic operations on the input signals, then a classification stage in which some features are extracted (FE) and manifested in some way to the user and eventually attributed to one of the subject VCA (discriminator), and, at the end, a stage in which a task can be executed.
Figure 1: Workflow of a biofeedback application.
Finally it is very frequent that these systems provide different operating modalities such as training, testing, setup, and running, that will be discussed in more detail in the next section.
This is a situation in which an object oriented programming (OOP) approach reaches his best results: inheritance, virtual functions and templates are all instruments created to reuse code and to allow generic programming, reducing the time required to implement a solution. In our case it is possible to describe the operative flow that is common to all biofeedback applications leaving to be defined only those aspects that are specific to the single implementation, such as the algorithms and the classification rules. Then, in a separate step, several systems can be realized just defining the points that are left unspecified. In this way it is possible to reduce the time necessary to build new systems, concentrating on classification algorithms only.
It is important to notice that the proposed solution does not make any assumption on both the operating system and the hardware used. For this reason all the aspects relative to the user interface and to the used devices or tools are intentionally left unspecified, even if it has been taken into account that a strong integration with them is required.
The object-oriented language used was C++, because of its diffusion, standardization, portability, performance, compatibility with C and because it is really easy to find a lot of libraries for matrix computation, DSP, and neural networks as well as a lot of acquisition board and tools that support it. Java could be a good solution too, but it actually does not still have a so huge diffusion and it generally produces relatively slower code. Furthermore, operating systems are mainly written in C or in C++ and even if the proposed framework must be independent with respect to them it must give the opportunity to use all the devices that can be used by disables already available on the various platforms. For example, it is easy to add to a C++ application the ability to use voice commands or text to speech engines, as well as tactile mice, screen readers or other input or output devices.
In the previous section the working flow of a biofeedback application has been illustrated. This constitutes the first step required to define an abstract model of it, for which it is necessary to know what are the elements that are common to all the implementations. Then, the specificity of a biofeedback application is given by the nature and types of the biological signals used, which must be possible to define for every single subject, and by the way in which a classification occurs. This last can be divided into two separate steps: the feature extraction and the discrimination rule. The former is relative to the computation of some parameters or measurements from the input biological signals while the latter is responsible of the attribution of the computed measures to one of the VCAs or to an undefined state. Because they characterize every biofeedback system, they can be defined only at the lower levels of the inheritance tree. However, it is known where they act in the flowchart of the generic application, and for this reason two virtual functions were declared, which must be overridden in every implementation.
Another aspect that is always encountered in different systems is the fact that it must operate in more ways. For this reason, the proposed model provides five modalities: training, testing, running, setup and pause. The training modality (fig. 2a) is relative to a period in which some parameters relative to the user are extracted in order to tune the system to him. During this phase, one asks to the subject to perform an action several times in order to collect some reference data that can be used later on by the classifier. This procedure is repeated for all the VCAs that the patient intends to use.
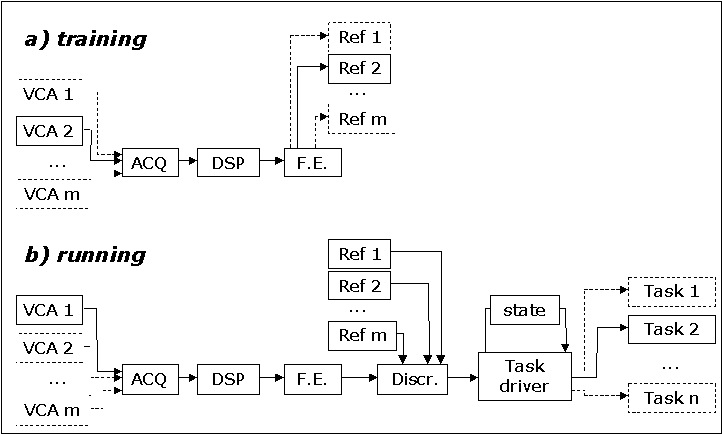 |
Figure 2: workflow of training and running modality.
The running modality (fig. 2b) is devoted to the identification of a VCAs and to the triggering of an event that might start an action in the case of a successful classification. The testing modality is somehow in the middle between the previous two: the system asks to the subject to perform one of the VCAs, and then try to classify it. After that, an internal score is updated and an event is triggered in order to signal a success or a failure. In this way it is possible to evaluate the performance of the whole system for every single performed task. The setup modality is relative to the hardware configuration and to the loading and saving of the references and other parameters computed during previous training sessions. Finally, in the pause mode the system is in an idle state.
Note that all these modalities can be implemented in the generic level: in testing modality, for example it is not important, to know how a classification occurs, but just if the VCA that was requested to the user was successfully recognized by the system.
In order to abstract the system from the platform used, then, some assumptions about the data format of the acquired signals must be done. Usually, they are stored in circular buffers that are mainly characterized by their size and data type (integer, floating point, etc.). In the case of different situations, it is easy to reproduce such one.
During the hardware initialization, at the startup of the program, the pointers to these buffers and other information such as sampling rate, number of inputs, and the data type that they contains are passed to the kernel layer. Then, every time that new samples are acquired, a notification function is called. Its role is twofold: on one side it informs that new data can be found on the buffers, giving all the information required to retrieve them, such as data offset and number of samples, on the other side, counting the number of the acquired samples, it is also possible to synchronize the timing of the whole system. Different operative modalities, in fact, has different needs: for example, during testing and running the classification must be performed continuously or at least every N milliseconds and on data segments of predefined length that may overlap; in training mode, instead, the feature extraction is generally executed over longer time intervals (several seconds) and on data segment whose length depends on the duration of the asked VCA and that must not overlap. Furthermore, extracted data can be used to update the reference measures, but after a consent.
All these features and many others are actually implemented in a class. From this class another one inherits, which adds matrix and FFT computation capabilities. As the used routines are written in ANSI C++ and they support several compilers on different platforms, this new class is still portable. Another derived class, that adds highly optimized DSP capabilities, is specific to Intel microprocessors and Win32 operating systems.
The implementation on a Wintel architecture of the Signal Space Projection algorithm [1] in a Brain Computer Interface application, which uses EEG activity as input signals, was realized. Less than 150 lines of C++ code so divided were necessary: 7 lines for reference measures computation, 15 lines for the discrimination rule, 44 lines for memory allocation and de-allocation and 75 lines for other tasks such as initialization, measures combination and change modality handling. Other 7 lines of code were required to adapt the existing acquisition routines. Data visualization, and user interface realization, which are specific to the used platform are not counted here.
A model for a generic biofeedback system was described. Its main advantages are the net separation of the blocks that are relative to the hardware, the input signals, the algorithms and the type and degree of disabilities. In this way it is possible to reuse a huge amount of code, thus minimizing the time required in the development and adaptation of a system to a wide number of patients.
[1] F. Babiloni, F. Cincotti, L. Lazzarini, J. Millàn, J. Mouriño, M. Varsta, J. Heikkonen, L. Bianchi and M.G. Marciani, “Linear classification of low-resolution EEG patterns produced by imagined hand movements”, IEEE Trans. Rehab. Eng, June 2000.